My employer uses CircleCI to run tests for each change before merging to the main branch. Faster tests means faster feedback cycles, which means you can ship more often. Shipping more often in turn means you gain more confidence shipping—it's a virtuous cycle.
Table of Contents
Introduction
In April the tests for one such Python Django application's PR workflow took about 13 minutes to run on CircleCI. We aimed to reduce this time to under 10 minutes. Picture 1 shows the most expensive part of our workflow at the start of our story.
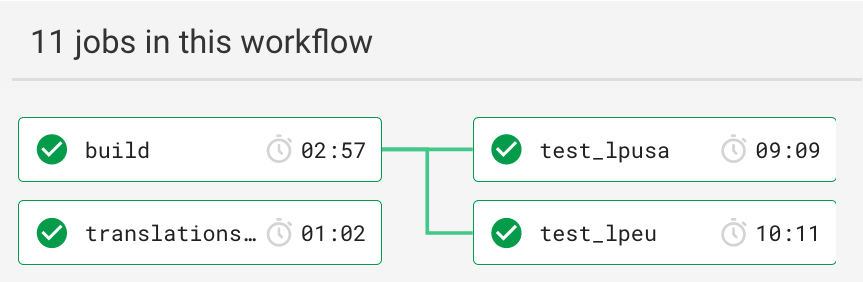
Figure 1: Starting Workflow (13m 24s)
What did the workflow do?
The build job created a Docker image, containing only runtime
dependencies1. It dumped this to a file with docker save, and
persisted it in the workspace. The two tests jobs2
restored the base image from the workspace. They built on this to
create an image with all the extra modules required to run the
tests. They then started dependencies, and ran the tests.
Doing shared setup once, then fan-out, is a time-honoured way to reduce resource usage. However our fan-out steps were expensive:
- Issuing
docker saveto dump the built image to a file took around 30 seconds, and persisting it to the workspace added another 60. - The test jobs then had to attach the workspace and load the base image, adding 30 seconds.
- Our test jobs started dependencies (Redis, Cassandra, and
PostgreSQL) with
docker-compose. This required us to use the machine executor, which added about 30-60 second startup overhead compared to the docker executors. - Because the base image from the
buildjob contained only runtime dependencies, we had to build a test docker image, extending the base to add dependencies for testing. Another 70-ish seconds.
That's adds up to a lot of time not yet running tests! Roughly half of the total time, in fact: when the tests finally started, they completed in about 6 minutes 30 seconds.
Why was workspace interaction so slow?
Our base image is big! I think mainly because the Docker python:2
image we started with is already big. This has a knock-on effect on
saving to, and restoring from, the workspace.
Analysis
It is possible we could have sped up the workspace interaction steps
by basing our Dockerfiles on a slimmer python:2 image. However this
would change what we deploy, and what engineers use locally. We
preferred to avoid that this time. (Although this is still on the
table for speeding up our deploy jobs.)
Our CircleCI PR workflow mimicked how most of our engineers used
docker-compose for local development: building a service image with
all runtime dependencies, and a test image that extended that with
tests and test dependencies. Using docker-compose was not required,
however. It was possible to run the tests directly with Tox—indeed
our Dockerfiles did this.
In a CI context you want to run all the tests in a freshly created environment with all the latest dependencies. Locally you won't typically create a new virtualenv and install dependencies anew every time you run tests, and you're more likely to cherry-pick relevant tests to run than run them all every time.
Remediation steps
We changed the CI test workflow to no longer depend on building the
base image3. We also changed our test jobs to launch
auxiliary services using CircleCI's docker executor native service
container support (rather than docker-compose), and run tox from
the main container to install dependencies and run tests. This
avoids minutes of saving the image to—and restoring it from—our
workspace. It also eliminated the extra startup-cost of the machine
executor.
Installing dependencies in the primary container on CircleCI, rather than relying on our Dockerfile, also allowed us to use CircleCI's caching to speed up virtualenv creation4. We didn't have access to this shared cache when installing dependencies into our docker images, but now it saved about 90 seconds when building the virtualenvs.
So far we've cut down the time preparing to run tests. Could we speed up the running of the tests themselves? On CI we don't need to keep the DB after test runs. Thus we replaced the DB image we used for tests with an in-memory Postgres image, that doesn't save to disk. This gave a modest reduction in test run time.
Finally we moved to running the tests in parallel, using Django's test runner. At first this resulted in lots of test failures related to our Cassandra integration5, but a couple of my colleagues were able to fix the problem. (As well as the new problem introduced by the first fix!) After a bit of trial and error we settled on running the tests in parallel across 3 CPUs6.
Figure 2 shows the result of the above steps. The workflow now completes comfortably in under four minutes—sometimes closer to three. Less time than the old workflow spent preparing to start running the tests!
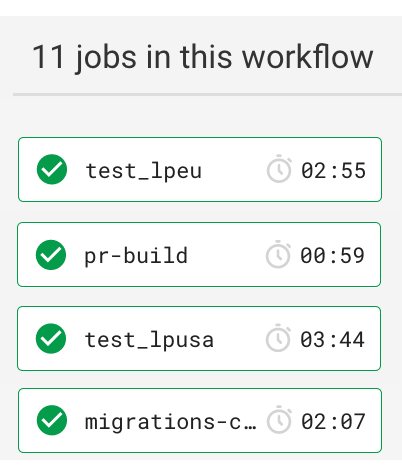
Figure 2: Final Workflow (3m 48s)
Conclusion
Speeding up our CI test runs was an exciting challenge that required a multi-pronged approach. There was no single change that gave a massive reduction on its own. Running tests in parallel, for example, would not have helped much when we spent most of the time preparing to run the tests.
The key came from recognising the differences between running tests in a CI vs local context. With this we were comfortable nudging our CI setup towards playing to the strengths of the CircleCI platform. This allowed us to iterate and unlock ways to improve test run time.
Acknowledgements
Thank you to Sławek Ehlert for valuable feedback that improved this article.
We don't want to add test dependencies to the base image, as in our deploy jobs (not discussed here) we deploy this on ElasticBeanstalk.
We deploy this application in two separate configurations with different feature sets. Each profile runs all the tests, except a small portion—about 10%—only applicable to the other profile.
We still build it, because we want to verify that we can. It is after all used in our deploy workflow still. But we no longer need to save it to disk, nor persist it to the workspace in our PR workflow.
In contrast to their example, however, we cache only PIP downloads, rather than the fully-built virtualenv. This to avoid any contamination that could creep into the virtualenv over time.
I then tried using CircleCI's test splitting instead. This showed promise, but it had problems: it was difficult to achieve an even split of the test files, since Django's test runner only accepts test module names. However, it prompted one of my colleagues to take a hard look at why the tests failed when running in parallel using Django's native method.
By default CircleCI gives you only 2 CPUs, but by upgrading to their new Performance Plan we were able to specify different resource classes for our jobs. This plan even saves us about one third off our monthly CircleCI bill! How? We hate queuing and on the old plan paid CircleCI for many containers. Most of our engineers are primarily based in one region, and all the containers were idle at night and all weekend. Paying only for what we use makes so much more sense!